Yeap,最终我还是从 Typecho 迁移到了 Hexo。
虽然 typecho 年久失修,诈尸 1.2 以后也没什么特别大的动静,各方面生态的缺失(主要是相关插件),再加上我的 php 写的一坨屎,插件 bug 了改都不怎么会改。
虽然 handsome 主题不开源,每个版本发布后我都得照着 patch 一个个打过去。
虽然动态博客一直有安全性问题,今天这个评论区被 spam 灌满了,明天那个后台被干了,后天又是什么存储 XSS。
纵使有这么多的问题,但是我实在是懒癌晚期,完全没救,实在是没什么干劲去迁移,只是看着我的朋友们都相继抛弃 wordpress 和 typecho 转向 Hexo Hugo 等一众静态博客,然后心底默默羡慕。
2025 年初,稻草最终还是被骆驼压死了,最后的压力来自我的主机商 失联 了。本来打算直接丢了得了,思来想去这博客还是写了点东西的,还是拿出了一些时间来迁移。
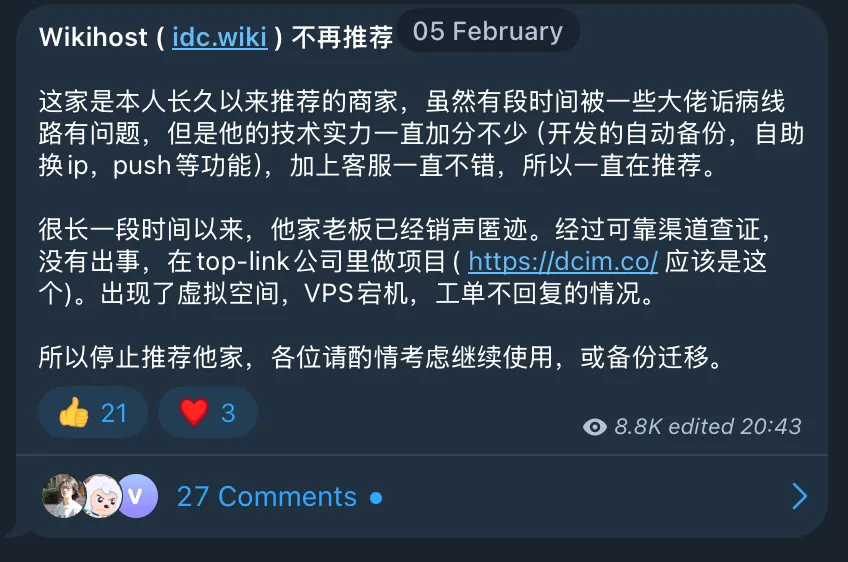
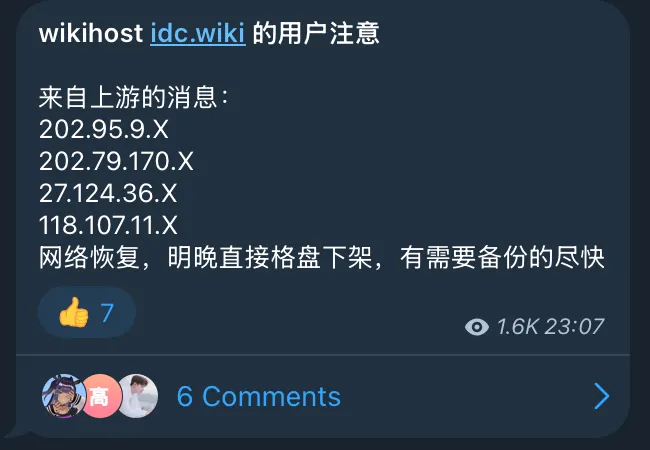
博客最终决定从 Typecho 迁移到 Hexo,主要原因是我实在是懒得再找一台机器放 blog 了,再加上动态博客搬一次家实在是过于麻烦,各种环境配置各种问题,还得提心吊胆会不会被人挂马。
索性直接迁移静态,丢在随便什么免费托管商上就好,CF、Github、vercel 都是可选项,源文件就直接丢 github 结束,正好图床都不用搭了。
洋洋洒洒写了这么多,还是进入正题吧。
大纲
先整理一下一下可能会遇到的麻烦
- 文章、图片和相关评论的迁移
- 相关 url 的跳转,避免迁移以后 SEO 直接寄了
- 相关插件的替换(比如高亮警示框)
文章、图片、评论的迁移
文章
最简单的一个,多亏了 typecho 的文章在数据库中也是 markdown 格式,不用做格式转换就可以无缝迁移,随便糊一个 python 就解决。
from datetime import datetime
from config import (
blog_mysql_db, blog_mysql_password, blog_mysql_host, blog_mysql_port, blog_mysql_user, blog_mysql_table_prefix,
ssh_host, ssh_password, ssh_port, ssh_user,
hexo_root_path
)
import pymysql
from sshtunnel import SSHTunnelForwarder
def fetch_posts(cursor, post_table_name):
cursor.execute(
f"SELECT * FROM `{post_table_name}` "
"WHERE `template` IS NULL AND `type`='post'"
)
return cursor.fetchall()
def fetch_metas(cursor, relationships_table_name, metas_table_name, post_id):
cursor.execute(
f'SELECT * FROM `{relationships_table_name}` '
f'JOIN `{metas_table_name}` '
f'ON `{relationships_table_name}`.`mid` = `{metas_table_name}`.`mid` '
f'WHERE `{relationships_table_name}`.`cid` = %s',
(post_id,)
)
return cursor.fetchall()
def generate_categories(metas):
categories = []
for meta in metas:
if meta[5] == 'category':
categories.append([meta[3], meta[4]])
if not categories:
return "None"
if len(categories) > 1:
return "\n" + "\n".join(f" - {c[0]}" for c in categories)
return categories[0][0]
def generate_tags(metas):
tags = [meta[4] for meta in metas if meta[5] == 'tag']
return tags
def save_post_to_file(num, slug, title, created, updated, tags, categories, content):
with open(f'{hexo_root_path}/source/_posts/{num}-{slug}.md', 'w', encoding='utf-8') as f:
f.write(f'''---
title: {title}
date: {created}
updated: {updated}
tags: [{','.join(tags)}]
categories: {categories}
---
{content}
''')
def main():
with SSHTunnelForwarder(
(ssh_host, ssh_port),
ssh_username=ssh_user,
ssh_password=ssh_password,
remote_bind_address=(blog_mysql_host, blog_mysql_port),
) as tunnel:
print("SSH 已连接")
connection = pymysql.connect(
host=blog_mysql_host,
port=tunnel.local_bind_port,
user=blog_mysql_user,
password=blog_mysql_password,
db=blog_mysql_db,
charset='utf8mb4'
)
print("数据库已连接")
try:
cur = connection.cursor()
post_table_name = blog_mysql_table_prefix + 'contents'
posts = fetch_posts(cur, post_table_name)
num = 1
for post in posts:
print(f"处理文章 {post[1]}")
content = post[5].removeprefix('<!--markdown-->')
title = post[1]
slug = post[2]
created = datetime.fromtimestamp(post[3]).strftime("%Y-%m-%d %H:%M:%S")
updated = datetime.fromtimestamp(post[4]).strftime("%Y-%m-%d %H:%M:%S")
relationships_table_name = blog_mysql_table_prefix + 'relationships'
metas_table_name = blog_mysql_table_prefix + 'metas'
metas = fetch_metas(cur, relationships_table_name, metas_table_name, post[0])
categories = generate_categories(metas)
tags = generate_tags(metas)
save_post_to_file(num, slug, title, created, updated, tags, categories, content)
print(f"文章 '{title}' 已保存")
num += 1
finally:
connection.close()
print("数据库已断开")
print("SSH 已断开")
if __name__ == "__main__":
main()除了 handsome 的一些 tag 需要自己手动搜索替换以外就没什么特别大问题了。
生成后的文件目录树是这样的:
source
├── _posts
│ ├── 1-start.md
│ ├── 21-How-to-Disassemble-Black-WoKong-UE-Assets.md
│ ├── 22-Migrating-from-Typecho-to-Hexo.md
...至于为什么要以数字开头,因为按照顺序排序看起来舒服,我喜欢。唯一的缺点就是 Hexo 默认以文章文件名创建路由,这样一来每个文章都得自己定义 permalink,不过倒也问题不大。
图片
原来的一些图片都是放在图床上的,而且非常不幸的是,图床服务器和博客服务器是同一台,所以以后也没有图床可以用了,所有图片都得丢到本地来了。
迁移图片也不那么难,读取 source/_post/*.md,找出 MD 中的图片链接,下载到本地并替换就好。
from config import hexo_root_path
import os
import re
import asyncio
from aiohttp import ClientSession
import hashlib
HEXO_SOURCE_PATH = os.path.join(hexo_root_path, 'source')
HEXO_POST_PATH = os.path.join(HEXO_SOURCE_PATH, '_posts')
async def download_image(url, path):
async with ClientSession() as session:
async with session.get(url) as response:
with open(path, 'wb') as f:
f.write(await response.read())
async def find_images_links_in_post(file_name):
post_path = os.path.join(HEXO_POST_PATH, file_name)
with open(post_path, 'r') as f:
content = f.read()
image_links = re.findall(r'!\[.*?\]\((.*?)\)', content)
return image_links
async def replace_image_links_in_post(post_file_name, old_link, new_link):
"""
例:
await replace_image_links_in_post(
post_file_name,
old_links=['https://old-link1.com/image1.png', 'https://old-link2.com/image2.png'],
new_links=['https://new-link1.com/image1.png', 'https://new-link2.com/image2.png']
)
旧 
旧 
新 
新 
"""
# 正则替换 ![]() 的链接,避免误伤
post_dir = os.path.join(HEXO_POST_PATH, post_file_name)
with open(post_dir, 'r', encoding='utf-8') as f:
content = f.read()
pattern = re.compile(r'(!\[.*?\])\(\s*' + re.escape(old_link) + r'\s*\)')
content = pattern.sub(f'\\1({new_link})', content)
with open(post_dir, 'w', encoding='utf-8') as f:
f.write(content)
async def download_images():
failed_downloads = {}
posts = sorted(os.listdir(HEXO_POST_PATH), key=lambda x: int(x.split('-')[0]))
for post_index, post in enumerate(posts, 1):
image_dir_path = os.path.join(HEXO_SOURCE_PATH, 'images', str(post_index))
if not os.path.exists(image_dir_path):
print(f"文章图片目录不存在,创建图片文件夹 {image_dir_path}")
os.makedirs(image_dir_path)
image_links = await find_images_links_in_post(post)
if not image_links:
print(f'{post} 无图片链接,跳过')
continue
for link_index, link in enumerate(image_links, 1):
image_path = os.path.join(HEXO_SOURCE_PATH, 'images', str(post_index), link.split('/')[-1])
if not os.path.exists(image_path):
print(f'下载 {link} 到 {image_path}')
try:
await download_image(link, image_path)
print(f'下载 {link} 成功,计算 sha1 并重命名文件中...')
with open(image_path, 'rb') as f:
image_hash = hashlib.sha1(f.read()).hexdigest()
image_new_path = os.path.join(HEXO_SOURCE_PATH, 'images', str(post_index), f"{image_hash}.{image_path.split('.')[-1]}")
os.rename(image_path, image_new_path)
# 替换文章中的图片链接
await replace_image_links_in_post(post, link, f'/images/{post_index}/{image_new_path.split("/")[-1]}')
except Exception as e:
print(f'下载 {link} 失败,错误信息:{e}')
if not post_index in failed_downloads:
failed_downloads[post_index] = []
failed_downloads[post_index].append(link)
else:
print(f'{link} 已存在,跳过')
if failed_downloads:
print('以下图片下载失败:')
for post_index, links in failed_downloads.items():
print(f'文章 {post_index}:')
for link in links:
print(link)
else:
print('下载完成')
asyncio.run(download_images())结束后的目录树则是这样的:
source
├── 404
├── images
│ ├── 10
│ │ └── 43f9210dbad8e78e2e9533a1ae1922b281ccd267.png
│ ├── 11
│ │ ├── 04c8626c4222d497d3e63ce2d639c7a40bf09d09.png
│ │ └── d8efdebc7a0a5391d32a282aefb192836a33046b.png
│ ├── 12
│ ├── 13
│ ├── 16
│ │ ├── 07d38625754d9676eedac8a5389acbd1768a6d49.jpg
│ │ ├── dff279f60ef4d697bdacde41610a0fa11451316a.jpg
│ │ └── e18ae6c55cef2462daba6dd1a6826ef859f95260.jpg
...所有图片均放在 imgaes 中,按照上面迁移文章时的编号创建文件夹,每个文章的图片均放在对应的文件夹中,图片命名使用 sha1,避免脚本写的不好图片重命覆盖了。
评论
由于 Hexo 原生没有评论系统,还得挑一个合适的评论系统。目前常见的评论系统有这几种
首先,国外的评论系统不纳入考虑范围,虽然部署方便,用起来也省心,但是要么是被富强,要么是在被富强的路上,真的不想在以后迁移一次评论系统了。
基于 GitHub 的评论系统都需要 GitHub 账号 OAUTH 后才能发表评论,这一步估计能劝退 99% 的人(包括我),也不考虑。
到这里选择基本不多了,可选项就是无后端评论系统了, valine 虽然哪哪都好,就是它是真·无后端,所有数据直达数据库,会带来 114514 个意想不到的问题。参考 基于 Serverless 的 Valine 可能并没有那么香
综合 UI、管理、迁移成本方面考虑,最终选了 waline 作为评论系统。
搭建 waline 确实不难,10 分钟之内解决,参考 官方教程 即可。
接下来就是迁移到 waline 了,waline 带了一个数据导入导出的页面,导入导出的格式均为 json,但是官方文档比较屎,亦或者是我脚本写到神志不清没有发现相关的文档,总之就是,我没有找到 waline 对这个 json 的定义。只能先装好 waline,自己 spam 自己几条垃圾评论后导出查看 json 格式。
{
"__version": "1.32.3",
"type": "waline",
"version": 1,
"time": 1739654656825,
"tables": [
"Comment",
"Counter",
"Users"
],
"data": {
"Comment": [
{
"objectId": "422a11c9bbf90017f9266572",
"comment": "欢迎加入 Typecho 大家族",
"insertedAt": "2020-01-28T14:57:10.000Z",
"createdAt": "2020-01-28T14:57:10.000Z",
"updatedAt": "2020-01-28T14:57:10.000Z",
"ip": "127.0.0.1",
"link": "http://typecho.org",
"mail": "",
"nick": "Typecho",
"ua": "Typecho 1.1/17.10.30",
"url": "/2020/01/28/start/",
"status": "approved"
},
{
"objectId": "073260d2a2aab013f5cf5155",
"comment": "测试测试\r\n",
"insertedAt": "2021-09-25T14:42:09.000Z",
"createdAt": "2021-09-25T14:42:09.000Z",
"updatedAt": "2021-09-25T14:42:09.000Z",
"ip": "1.1.1.1",
"link": "https://blog.ixiaocai.net",
"mail": "",
"nick": "XiaoCai",
"ua": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.131 Safari/537.36 Edg/92.0.902.67",
"url": "/2020/01/28/start/",
"status": "approved",
"pid": "422a11c9bbf90017f9266572",
"rid": "422a11c9bbf90017f9266572"
}
],
"Counter": [
{
"url": "/2020/01/28/start/",
"time": 1,
"objectId": "9bd4270f2b21196ebd4daca4",
"createdAt": "2020-01-28T14:57:00.000Z",
"updatedAt": "2024-08-27T00:49:10.000Z"
}
],
"Users": []
}
}可以注意到,json 里还有一个 Counter 字段,意味着我们不用再去找别的插件来实现流量量记录了,而在迁移评论的时候顺带给文章的浏览量也一并迁移。
import pymysql
import json
from datetime import datetime
from sshtunnel import SSHTunnelForwarder
from config import blog_mysql_db, blog_mysql_password, blog_mysql_host, blog_mysql_port, blog_mysql_user, blog_mysql_table_prefix
from config import ssh_host, ssh_password, ssh_port, ssh_user
from hashlib import sha1
import os
import random
import string
WALINE_COMMENT_TEMPLATE = {
"__version": "1.32.3",
"type": "waline",
"version": 1,
"time": 1739654656825,
"tables": [
"Comment",
"Counter",
"Users"
],
"data": {}
}
HASHLIB_SEED = ''.join(random.choices(string.ascii_letters + string.digits, k=32))
PAGE_MAP = {
"/2024/04/16/SettingUp-Global-Proxy-for-Liunx/": "/2024/04/16/SettingUp-Global-Proxy-for-Linux/",
"/2021/08/11/how_to_use_irc/": None,
"/2020/05/11/board/": None,
"/2020/02/06/about/": None,
"/2020/01/29/cross/": None,
}
class Export2Waline:
def __init__(self):
self.comment_hash = {}
def get_root_id(self, comment_id):
parent_id = self.comment_hash.get(comment_id)
if not parent_id:
return comment_id
return self.get_root_id(parent_id)
def do_export(self):
with SSHTunnelForwarder(
(ssh_host, ssh_port),
ssh_username=ssh_user,
ssh_password=ssh_password,
remote_bind_address=(blog_mysql_host, blog_mysql_port),
) as tunnel:
connection = pymysql.connect(
host=blog_mysql_host,
port=tunnel.local_bind_port,
user=blog_mysql_user,
password=blog_mysql_password,
db=blog_mysql_db
)
try:
cursor = connection.cursor(pymysql.cursors.DictCursor)
post_count_results = []
content_dict = {}
cursor.execute(f"SELECT * FROM {blog_mysql_table_prefix}contents WHERE `type` IN ('post', 'page')")
tp_contents = cursor.fetchall()
for content in tp_contents:
content_dict[content["cid"]] = {
"slug": content["slug"],
"created": content["created"],
}
url = f"/{datetime.utcfromtimestamp(content['created']).strftime('%Y/%m/%d')}/{content['slug']}/"
if url in PAGE_MAP:
if PAGE_MAP[url] is None:
continue
url = PAGE_MAP[url]
post_count_results.append(
{
"url": url,
"time": content["views"],
"objectId": (sha1(str(random.randbytes(128)).encode()).hexdigest())[0:24],
"createdAt": datetime.utcfromtimestamp(content["created"]).strftime("%Y-%m-%dT%H:%M:%S.000Z"),
"updatedAt": datetime.utcfromtimestamp(content["modified"]).strftime("%Y-%m-%dT%H:%M:%S.000Z"),
}
)
cursor.execute(f"SELECT * FROM {blog_mysql_table_prefix}comments")
tp_comments = cursor.fetchall()
for comment in tp_comments:
if comment["parent"] == 0:
continue
self.comment_hash[comment["coid"]] = comment["parent"]
comment_results = []
for comment in tp_comments:
slug = (content_dict.get(comment["cid"])).get("slug")
# 按照 / + year + month + day + slug 的格式生成文章链接
post_create_time = datetime.utcfromtimestamp((content_dict.get(comment["cid"])).get("created")).strftime("%Y/%m/%d")
post_url = f"/{post_create_time}/{slug}/"
# 根据全局的 map 来映射文章链接,有些链接在 hexo 里已经更改过了
if post_url in PAGE_MAP:
if PAGE_MAP[post_url] is None:
continue
post_url = PAGE_MAP[post_url]
comment_time = datetime.utcfromtimestamp(comment["created"]).strftime("%Y-%m-%dT%H:%M:%S.000Z")
comment_text = comment["text"]
if ("[secret]" in comment_text) and ("/secret" in comment_text):
status = "waiting"
else:
status = comment["status"]
comment_result = {
"objectId": sha1(f"{comment['coid']}_{HASHLIB_SEED}".encode()).hexdigest()[0:24],
"comment": comment_text,
"insertedAt": comment_time,
"createdAt": comment_time,
"updatedAt": comment_time,
"ip": comment["ip"],
"link": comment["url"],
"mail": comment["mail"] if comment["mail"] else "",
"nick": comment["author"] if comment["author"] else "匿名",
"ua": comment["agent"] if comment["agent"] else "",
"url": post_url,
"status": status,
}
if comment["parent"]:
# 生成的 json 中:
# pid -> 父评论的 objID
# rid -> 根评论的 objID
#
# 在原来的 DB 中:
# cid == 对应文章的唯一 ID
# coid == 评论的唯一 ID
# parent == 父评论的唯一 ID
# rid 所以需要一路找上去,直到找到根评论的唯一ID
comment_result["pid"] = (sha1(f"{comment['parent']}_{HASHLIB_SEED}".encode()).hexdigest())[0:24]
comment_result["rid"] = (sha1(f"{self.get_root_id(comment['coid'])}_{HASHLIB_SEED}".encode()).hexdigest())[0:24]
comment_results.append(comment_result)
# 拼装
WALINE_COMMENT_TEMPLATE["data"]["Comment"] = comment_results
WALINE_COMMENT_TEMPLATE["data"]["Counter"] = post_count_results
WALINE_COMMENT_TEMPLATE["data"]["Users"] = []
# 备份到 json
file_name = f'blog_comments.{datetime.today().strftime("%Y-%m-%d")}.json'
file_path = os.path.join("./", 'exported_comments', file_name)
os.makedirs(os.path.dirname(file_path), exist_ok=True)
with open(file_path, 'w', encoding='utf-8') as file:
json.dump(WALINE_COMMENT_TEMPLATE, file, ensure_ascii=False, indent=2)
print(set([x["url"] for x in comment_results]))
finally:
connection.close()
if __name__ == "__main__":
export_action = Export2Waline()
export_action.do_export()URL 跳转和 SEO 处理
Hexo 的默认配置启用了链接美化,自动移除末尾的 .html。
嗯,正好我也不喜欢后缀,所以选择不修改链接美化,但是很要命的是,我修改了每个文章的的文件名,导致了 Hexo 默认的路由变为了 索引-文章名。所有文章的路由都变了,意味着所有原来的文章均会 404。而搜索引擎发现你的页面 404 就会降权重,虽然小破站没啥人看,流量也不大,但是强迫症犯了,我就是要修好这个。
由于 Hexo 是静态页面,前端完全没法实现 301 的跳转,只是机械的 location.replace 太粪了,一坨大便。还好 vercel 提供了接口来实现跳转。
{
"redirects": [
{
"source": "Migrating-from-Typecho-to-Hexo.html",
"destination": "/2025/02/16/Migrating-from-Typecho-to-Hexo/",
"permanent": true
}
]
}现在就是手动标定 source 和 destination 即可,在 front-matter 中添加 permalink 和 alias 便可以用 js 生成一个适用于 vercel 的重定向文件。
感谢 copilot 救我命,自动补全太适合这种机械化但又不值得写脚本的场景了
比如我需要从 Migrating-from-Typecho-to-Hexo.html 跳转到 /2025/02/14/Migrating-from-Typecho-to-Hexo/,则在文章开头添加如下:
permalink: /2025/02/14/Migrating-from-Typecho-to-Hexo/
alias:
- Migrating-from-Typecho-to-Hexo
- Migrating-from-Typecho-to-Hexo.html然后在根目录下新建 script 新建一个 js 写入下面脚本,hexo clean && hexo g 即可看到控制台中打印出的 json,丢在根目录下的 vercel.json 中即可。
function get_redirects(locals) {
let json_template = {"redirects": []}
for (let post of locals.posts.data) {
if (! post.permalink) {
return;
}
let alias = post.alias;
if (alias) {
for (let a of alias) {
json_template.redirects.push({
"source": a,
"destination": post.__permalink,
"permanent": true
});
}
}
}
hexo.log.info(JSON.stringify(json_template, null, 2));
}
hexo.extend.generator.register('alias', get_redirects);此外,vercel.json 中还支持服务端美化链接,完美符合我的需求,只需要一行:"cleanUrls": true 即可,更多说明。
相关插件的替换
讲道理,我本身也没有装太多花里胡哨的插件,基本没啥替换的插件,我需要的功能 Next 基本都支持了。
抛开主题方和 Hexo 官方提供的插件,装的第三方的插件可能就这些:
- @waline/hexo-next 评论插件
- hexo-word-counter 字数统计、阅读时间估计
- hexo-bilibili-plus 文章嵌入 bilibili 视频
- 文章时效性提醒
- hexo-html-ruby 效果就是你左边看到的那样
禁用 category 和 tag 页面下的搜索引擎索引
hexo.extend.injector.register('head_begin', '<meta name="robots" content="noindex">', 'category');
hexo.extend.injector.register('head_begin', '<meta name="robots" content="noindex">', 'tag');自定义 vercel 的 404 页面
先使用 hexo new page 404 创建一个页面,写入这些
---
title: 抱歉,页面未找到
sidebar: false
noindex: true
comments: false
---
您请求的页面不存在,它可能已被删除,或者是受到了本博客迁移的影响...
请尝试使用 <a role="button" class="popup-trigger"><i class="fa-fw"></i>搜索</a> 或者返回 [首页](/)。
{% raw %}
<style>
.post-title {
text-align: center;
}
.post-body {
text-align: center;
margin-top: 20px;
}
</style>
{% endraw %}由于 vercel 只认根目录下的 404.html,完全不认 /404/ 所以还需要往根目录下复制一份生成好的 404 页面
// 将生成的 404 页面复制到根目录一份,方便在 vercel 提示 404 的时候显得不那么丑
hexo.extend.filter.register('before_exit', function() {
const fs = require('fs');
const path = require('path');
// 检查目录是否存在
if (!fs.existsSync(path.join(hexo.public_dir, '404'))) {
return;
}
const source = path.join(hexo.public_dir, '404', 'index.html');
const dest = path.join(hexo.public_dir, '404.html');
fs.copyFileSync(source, dest);
});自己改的 ruby 插件
ruby 插件的话我没有作为库,而是直接丢到了 script 下,其余均可以直接使用 npm install <插件名> --save 安装。
const { pinyin } = require("pinyin");
hexo.extend.tag.register('ruby', function(args) {
const splited = args.join(' ').split('|');
const origin = splited[0].trim();
let ruby = origin;
if (splited.length > 1) {
ruby = splited[1].trim(); // 如果有自定义注音,使用自定义注音
}
const pinyinResult = pinyin(ruby, {
style: pinyin.STYLE_TONE,
segment: true, // 启用分词
heteronym: false // 不启用多音字
});
return `<ruby>${origin}<rp> (</rp><rt>${pinyinResult.map(item => item[0]).join(' ')}</rt><rp>) </rp></ruby>`;
});